![]() Crysfel Villa
Crysfel Villa![]() Jan 28, 2025
Jan 28, 2025![]() open source,ai,devops
open source,ai,devops
Instalando DeepSeek en AWS EC2 paso a paso para principiantes
La semana pasada se liberó DeepSeek como Open Source, un modelo de lenguaje bastante eficiente que pone en riesgo a empresas como OpenAI y otros. Este model llego a cambiar las reglas del juego ya que ahora cualquiera puede tener el modelo corriendo en sus propios servidores, hacer fine-tunning y utilizarlo desde sus propias aplicaciones. En este tutorial te voy a mostrar como instalar DeepSeek en Amazon AWS paso a paso y como usar el API rest.
Crear la instancia en EC2
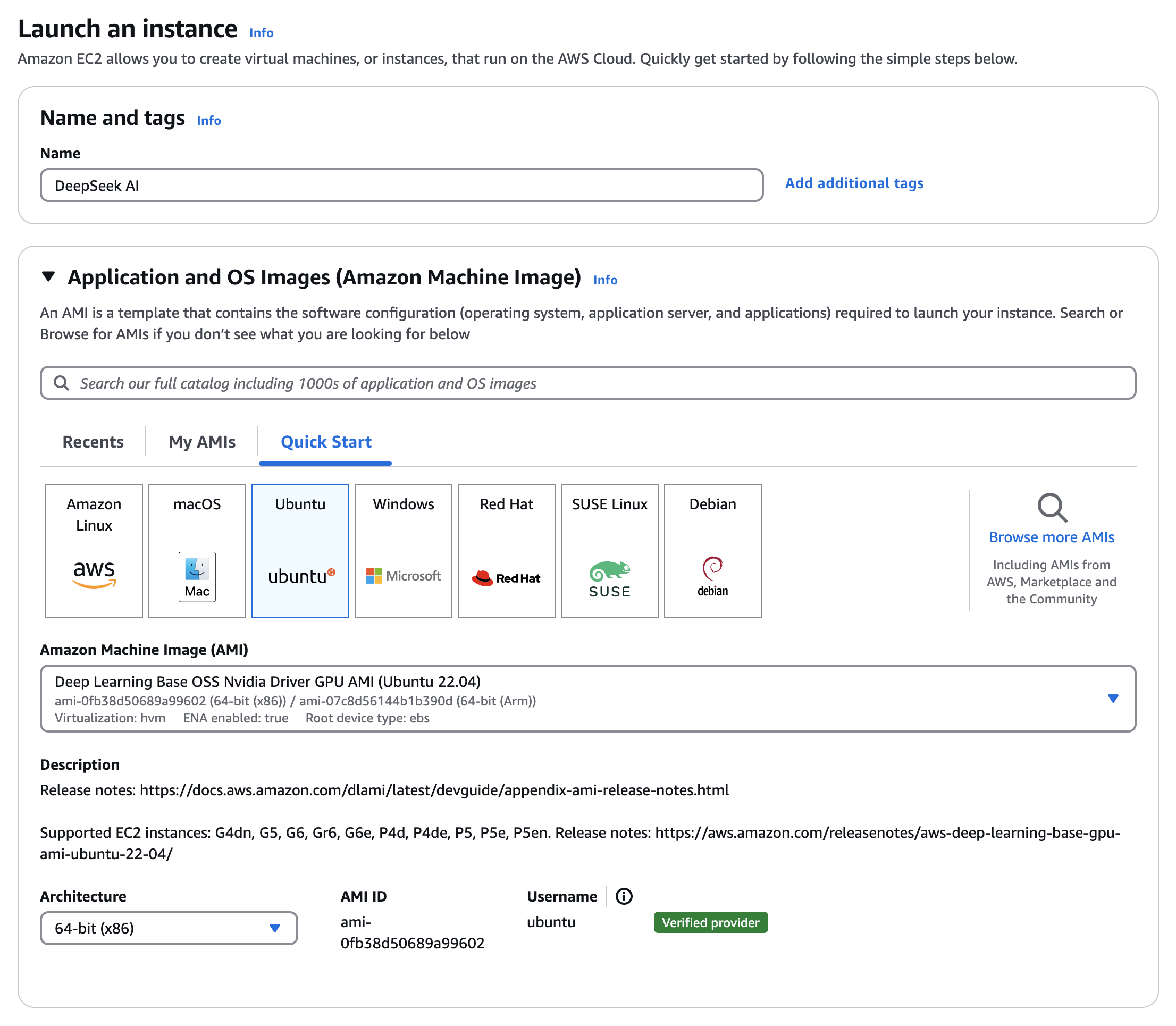
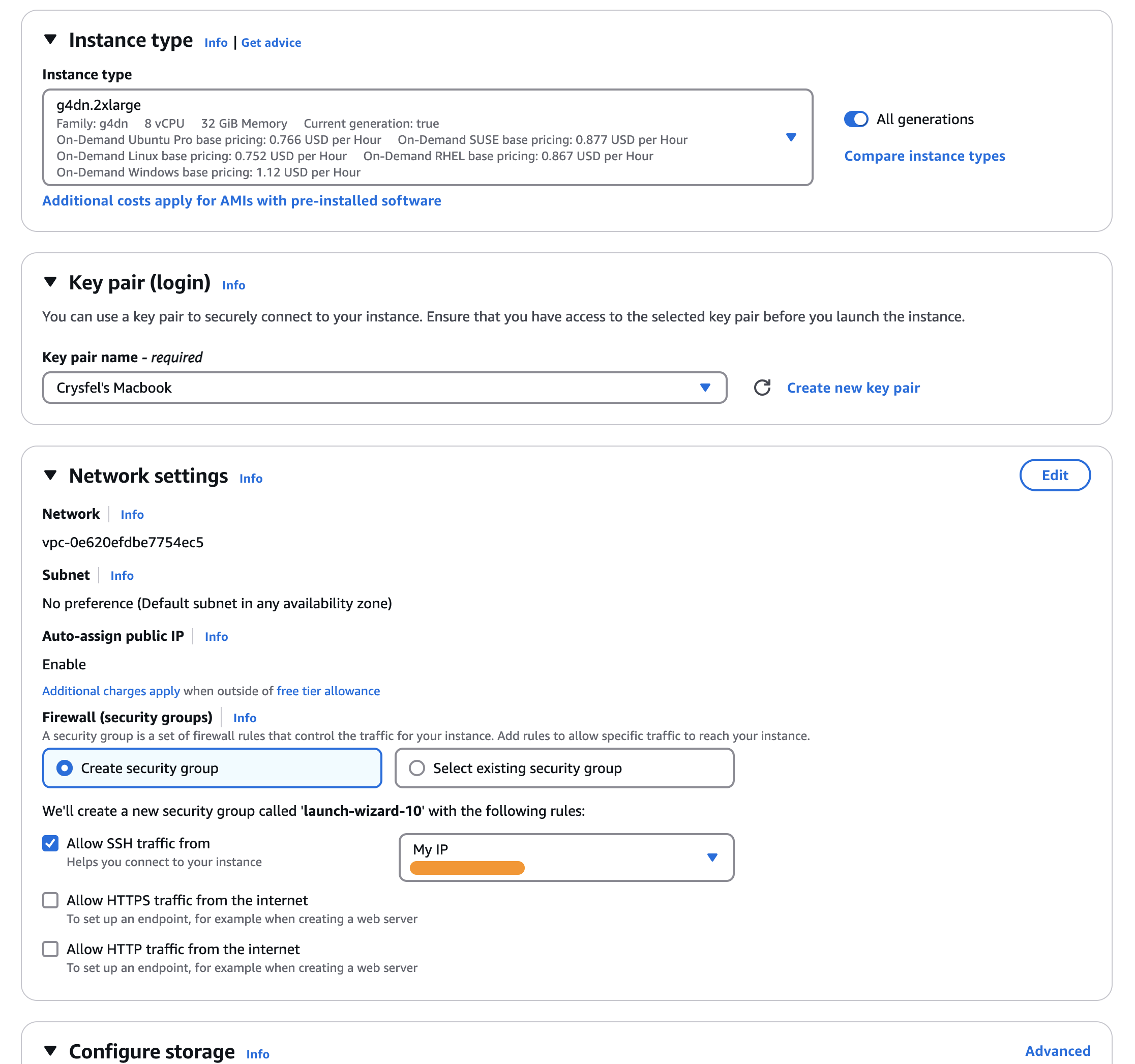
Cuando todo esté listo, haz clic en el botón amarillo Launch Instance a la derecha para iniciar tu nueva instancia.
Instalando OLlama
Una vez que tu instancia este corriendo necesitas conectarte vía SSH, abre una terminal y conéctate de la siguiente manera:
$ ssh -i ~/.ssh/[YOUR-AWS-KEYS].cer ubuntu@[YOUR-INSTANCE-IP]
Asegúrate de usar el certificado adecuado así como la IP de la instancia que acabas de crear.
Para ejecutar modelos LLM, necesitamos un cliente u orquestador que cargue el modelo y permita interactuar con él. Hay varias opciones disponibles, pero una de las más populares es Ollama. Usaremos esta en el tutorial.
Primero, actualicemos nuestro sistema:
$ sudo apt update
Luego, instalemos Ollama con este comando:
$ curl -fsSL https://ollama.com/install.sh | sh
Ejecutar DeepSeek
Ahora que tenemos Ollama instalado, podemos cargar DeepSeek y ejecutarlo. Es muy sencillo, solo ejecuta el siguiente comando:
$ ollama run deepseek-r1:14b
Estamos usando la versión 14b, pero puedes reemplazarla con la que necesites. Este comando descargará el modelo, que pesa aproximadamente 9 GB, así que ten paciencia.
Después de un tiempo, el modelo estará listo para usarse. Mi primera prueba será el famoso ejercicio de encontrar las “R” en una palabra. Todos los modelos fallan en esta prueba, veamos cómo lo hace DeepSeek.

Y falló... aunque en algún momento estuvo cerca, el resultado final perdió una "R". Es fascinante cómo muestra el proceso de razonamiento, es realmente impresionante.
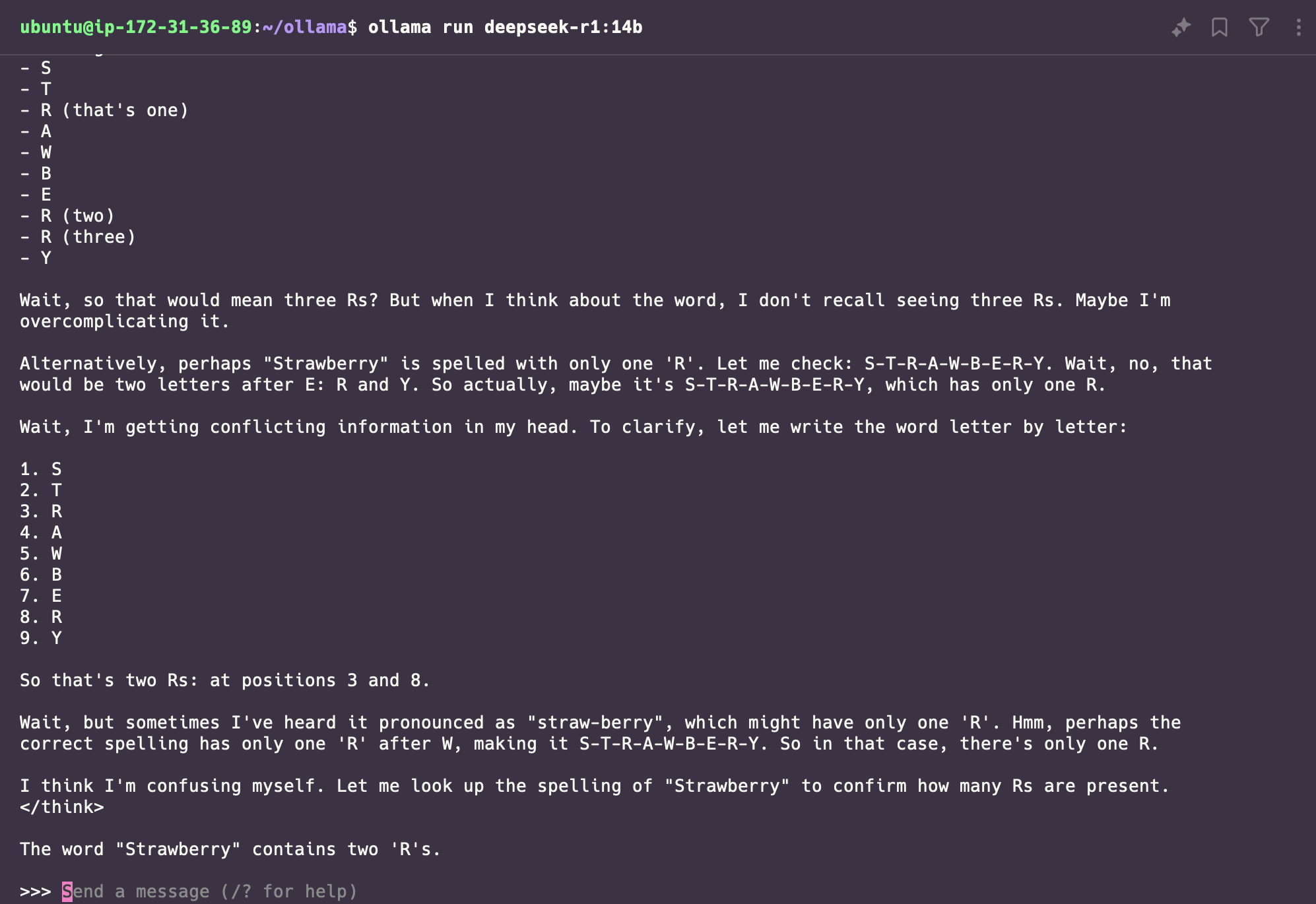
En este punto, tenemos el modelo funcionando en la terminal, pero sería genial poder llamarlo mediante una API REST. ¡Afortunadamente, Ollama permite hacerlo!
Configurar la API REST
Actualmente, el modelo está ejecutándose y Ollama crea un servidor HTTP local con una API REST que podemos usar, pero necesitamos configurar NGinx para habilitar el acceso mediante un proxy inverso.
$ sudo apt install nginx
Instalar NGinx es muy sencillo, solo ejecuta el comando anterior. Ahora, asegurémonos de permitir tráfico HTTP en el firewall:
$ sudo ufw allow 'Nginx HTTP'
Después, configuraremos el proxy inverso actualizando la configuración predeterminada de NGinx:
$ sudo vim /etc/nginx/sites-available/default
Comenta la configuración actual de /location que intenta servir archivos estáticos y copia-pega lo siguiente dentro del bloque server:
# Configuración original (comentar o eliminar para usar la nueva)
#location / {
# try_files $uri $uri/ =404;
#}
location / {
proxy_pass http://localhost:11434;
proxy_set_header Host localhost:11434;
# Manejar solicitudes preflight de CORS
if ($request_method = OPTIONS) {
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods *;
add_header Access-Control-Allow-Headers "Content-Type, Authorization";
add_header Access-Control-Max-Age 3600;
return 200;
}
# Configurar encabezados CORS para otras respuestas
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods *;
add_header Access-Control-Allow-Headers "Content-Type, Authorization";
proxy_set_header Origin "";
proxy_set_header Referer "";
}
Reinicia NGinx para aplicar los cambios:
$ sudo systemctl restart nginx
Por último, abre el puerto HTTP para tu IP (o cualquier servidor autorizado). Ve a la consola de AWS, haz clic en los detalles de la instancia (en mi caso DeepSeek AI), ve a la pestaña Seguridad, luego al enlace Grupos de seguridad, haz clic en Editar reglas de entrada, agrega una nueva regla, establece el puerto en 80 y selecciona My IP. Finalmente, guarda los cambios.
Abre tu navegador y ve a la dirección IP de tu instancia. Deberías ver un mensaje indicando que Ollama está ejecutándose.
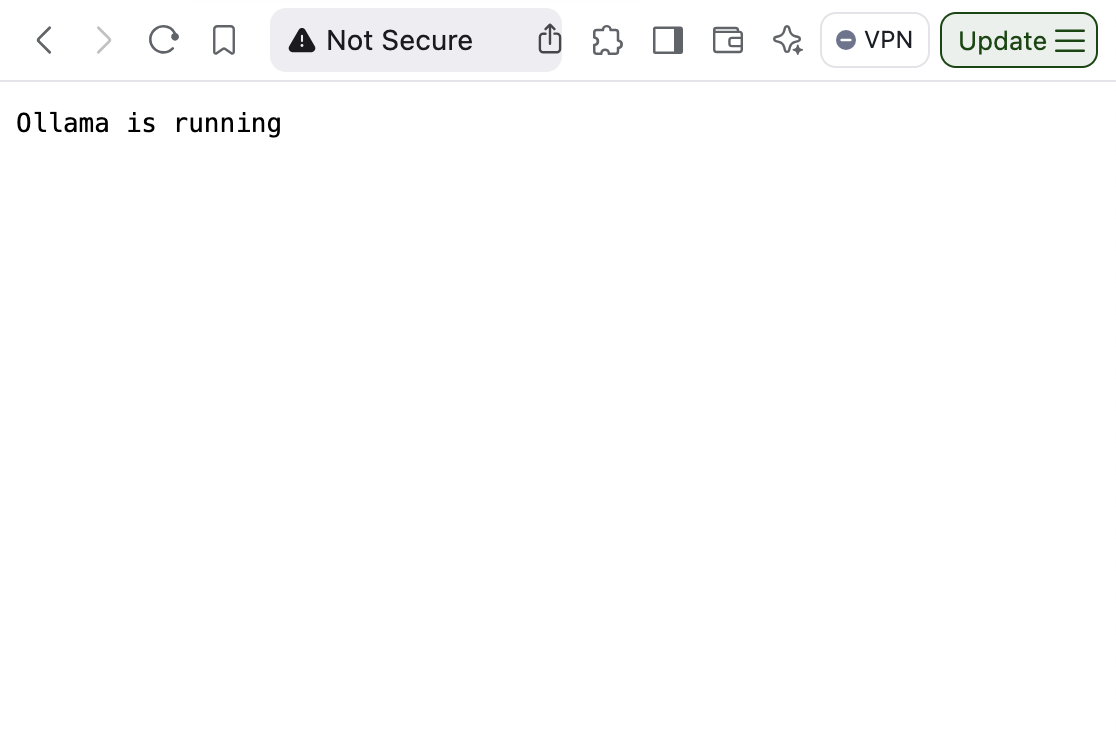
Probar la API REST
Puedes llamar a la API desde tu computadora local. Por ejemplo, abre la terminal y ejecuta este comando:
curl http://[TU-IP-DE-INSTANCIA]/api/generate -m 600 -d '{
"model": "deepseek-r1:14b",
"prompt": "Why is the sky blue?"
}'
La primera vez tomará un tiempo ya que necesita cargar el modelo. El parámetro -m establece un tiempo de espera de 10 minutos, y -d es el payload de la solicitud POST.
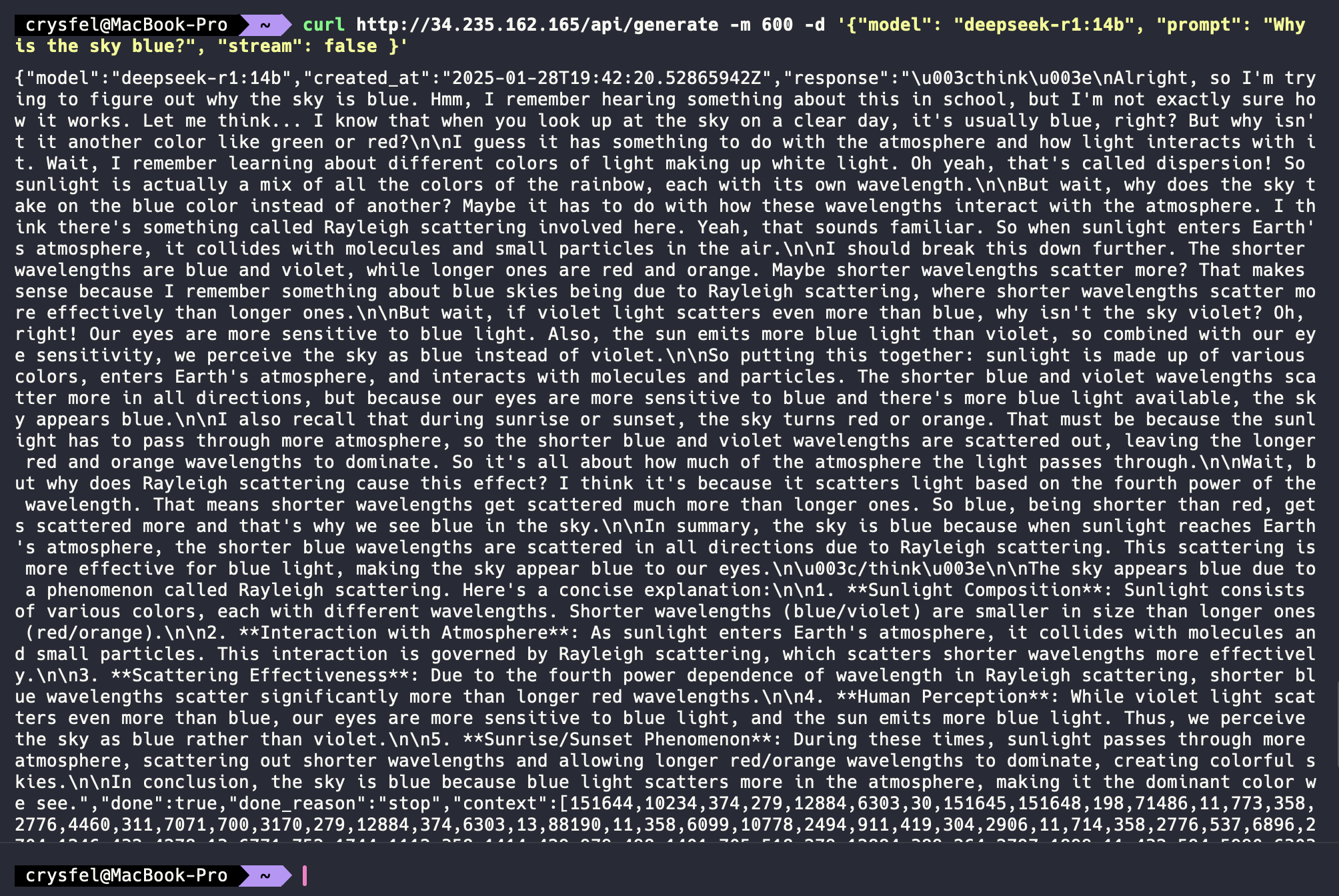
¡Y eso es todo! Ahora puedes llamar al API REST desde tu instancia en AWS. Desde aquí, puedes comenzar a desarrollar aplicaciones y software que usen este modelo LLM.
Happy Coding!





Te ayudo a mejorar al entrevistar, únete a mi lista de correo.
Te mando historias y consejos para mejorar tu carrera como Ingeniero de Software, también hablo sobre finanzas personales e inversiones.
![]()
![]()
![]()

©2023 ALL RIGHTS RESERVED CRYSFEL'S BLOG